低配置电脑AI翻唱全教程
小白教程 谨慎科学食用
本文所使用的网站&软件
- 音乐免费下载平台(MyFreeMP3):https://www.myfreemp3.com.cn/
- Google的Colab实验平台:https://colab.research.google.com/
- AutoDL算力平台:https://www.autodl.com/
- Adobe Audition 2025版
素材收集
被AI者的声音素材
- 因为被AI者母语不是中文,但演绎歌曲为中文,所以准备了4个3-10分钟的音频,分别是1个采访音频、2个唱歌音频(最好是Live版)、1个被AI者中文音频
演绎歌曲
- 《最后一页》【最好不要合唱歌曲】
TIPS:Youtube或B站的视频不支持页面直接下载,可借用下面两个网站下载。
Youtube视频下载网站:https://yt1ss.pro/zh-cn199/
B站视频下载网站:https://snapany.com/zh/bilibili
音频分离
本教程使用的音频分离模型MSST-WebUI,是B站开源UP主花儿不哭基于原UVR5的基础融合迭代更新,是目前最新最有用的音频分离模型。
- MSST-WebUI项目开源地址:https://github.com/SUC-DriverOld/MSST-WebUI
- 开源UP主超详细零帧起手教程:https://r1kc63iz15l.feishu.cn/wiki/JSp3wk7zuinvIXkIqSUcCXY1nKc
云端训练:Colab需要挂梯子且每天只能白嫖2小时,AutoDL网站的4090主机每小时2块钱左右。
Colab云端音频分离教程
- MSST云端使用教程:https://r1kc63iz15l.feishu.cn/wiki/IupAwjospiOQVLkQOsRcpGVznAg
- Colab项目地址:https://colab.research.google.com/github/SUC-DriverOld/MSST-WebUI/blob/main/webUI_for_colab.ipynb
第一步:打开WebUI界面。
- 直接打开项目地址即可进入项目,登入Gmail邮箱帐号,其余内容参考MSST云端使用教程,逐一运行所有代码,点击出现的WebUI链接即可进入操作界面。
PS:如果运行一次后WebUI界面不出现,重新再运行一次即可。两个压缩包input.zip和Outputs.zip需要上传在MyDrive下面(好像也可以不上传,反正我传了)
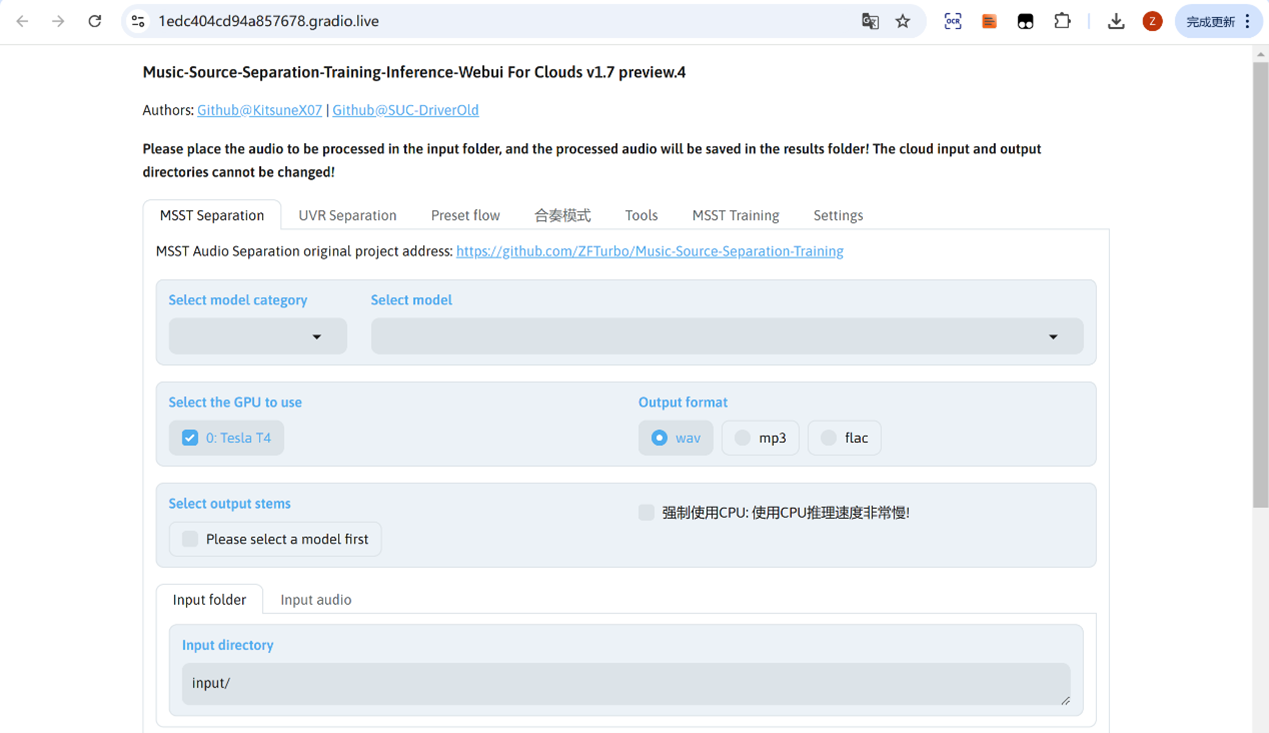
第二步:上传文件进行音频分离
MSST模型
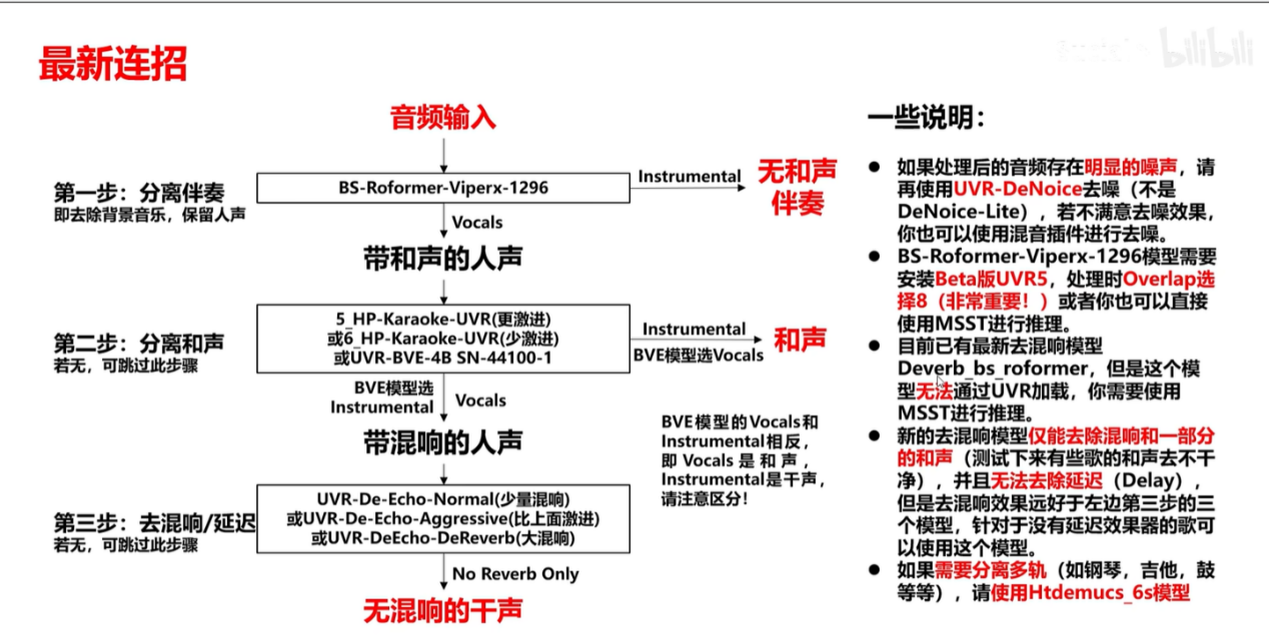
- 普通去除:Kim_MelBandRoformer + deverb_bs_roformer_8_256dim_8depth
- 中间加入去和声模型使用模型(觉得普通去除不够好):Kim_MelBandRoformer + mel_band_roformer_karaoke_aufr33_viperx_sdr_10.1956 + deverb_bs_roformer_8_256dim_8depth

- Select model category处选择对应的模型项目,Select Model处选择对应的模型。
- Output format处可选择三种类型【wav高质但内存大(4分钟的歌曲70M左右),下载分离文件时会比较慢;mp3一般但内存小(4分钟的歌曲8M左右),flac暂时没试,建议选wav】
- 点击Input audio将文件拖拽上传,点击音频分离。
第三步:下载分离好的音频
- 完成后分离的音频会被放在WebUI的results下面,点击下载即可。
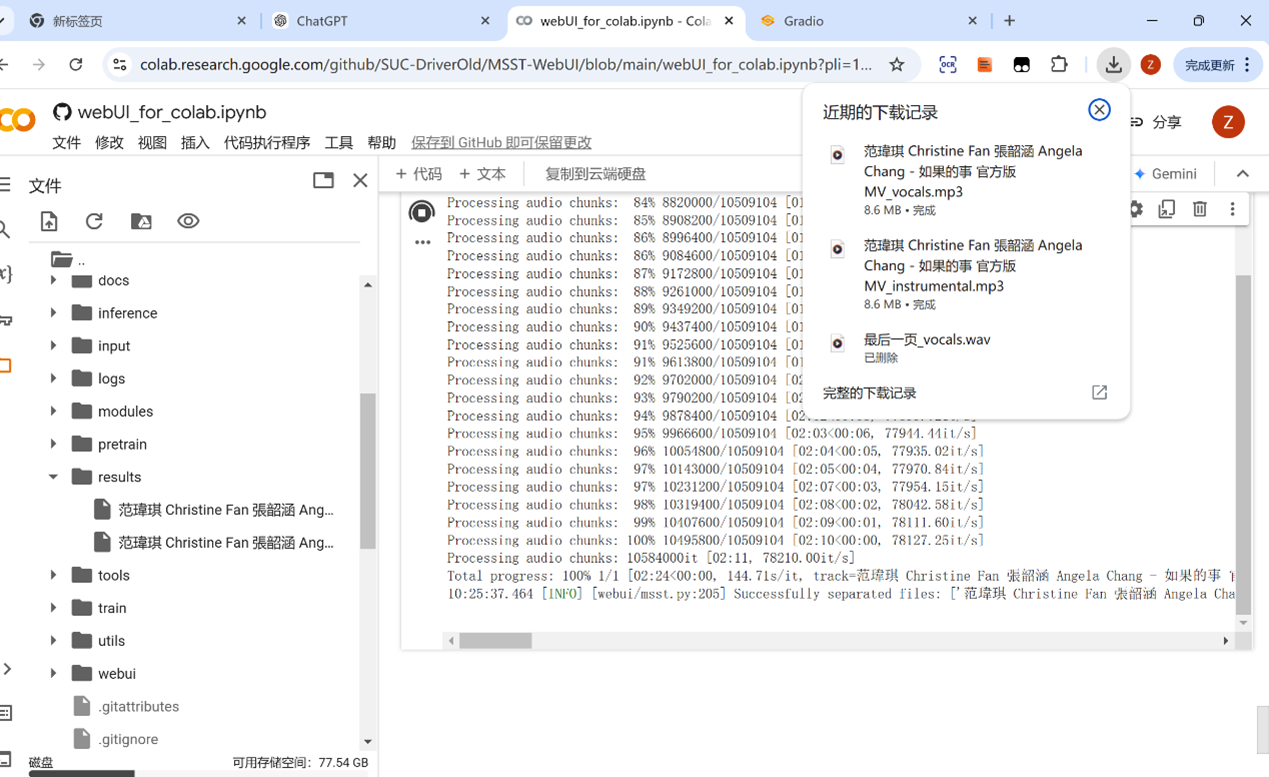
第四步:重复第二步第三步的步骤
- 将上述第三步得到的人声音频重复第二步去和音去混响。若试听分离音频已经没有和音混音,则不需要进行分离,一般进行三次分离后就可以得到很干净的干声音频。
AutoDL云端音频分离教程
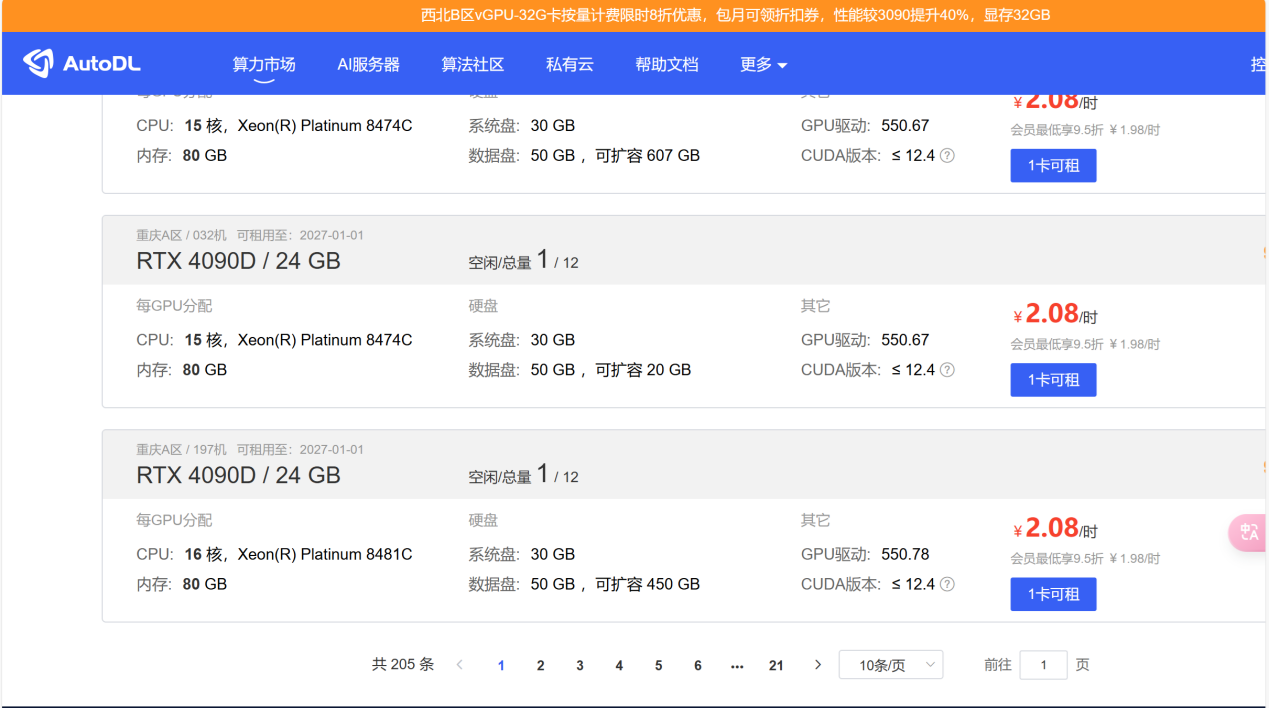
第一步:创建训练主机
- 打开网站地址,选择一台空闲的主机,点击社区镜像,搜索框输入MSST后,选择其中一个【开源UP说哪个都可以,所以选了个最新的】,点击立即创建。
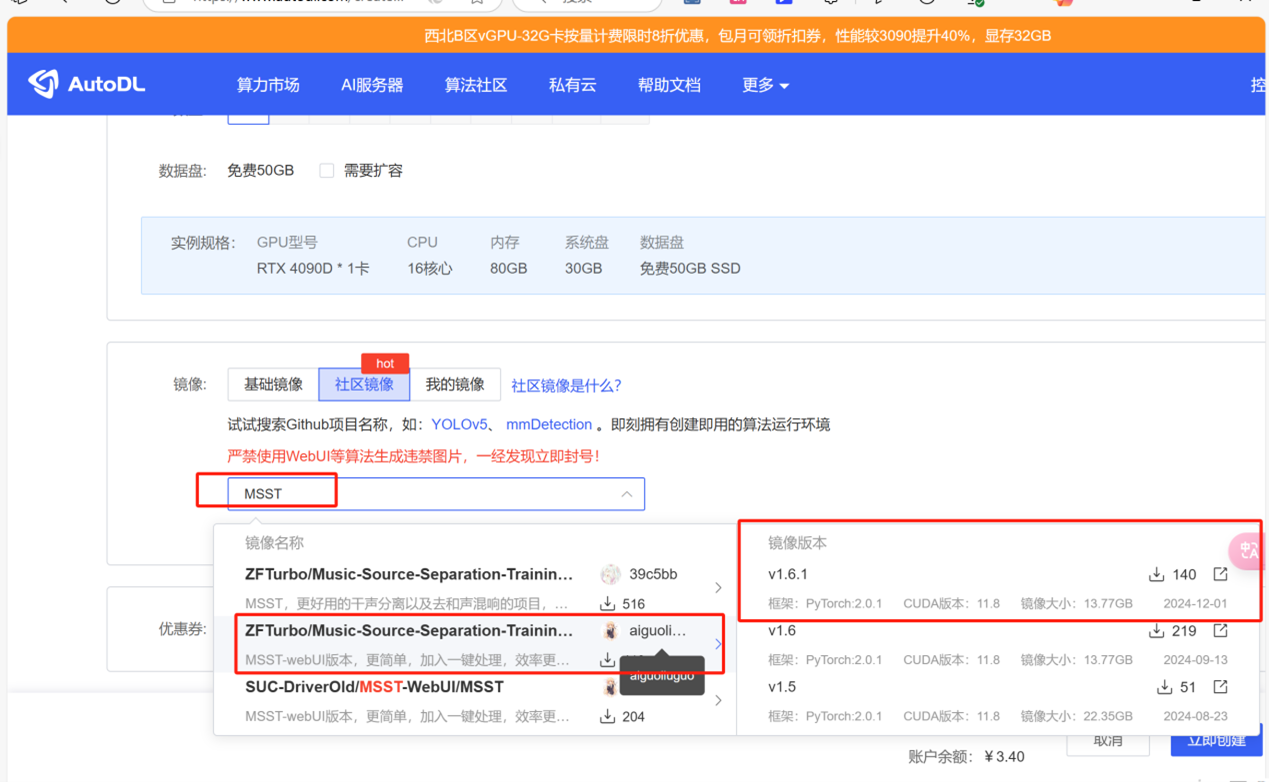
第二步:音频分离
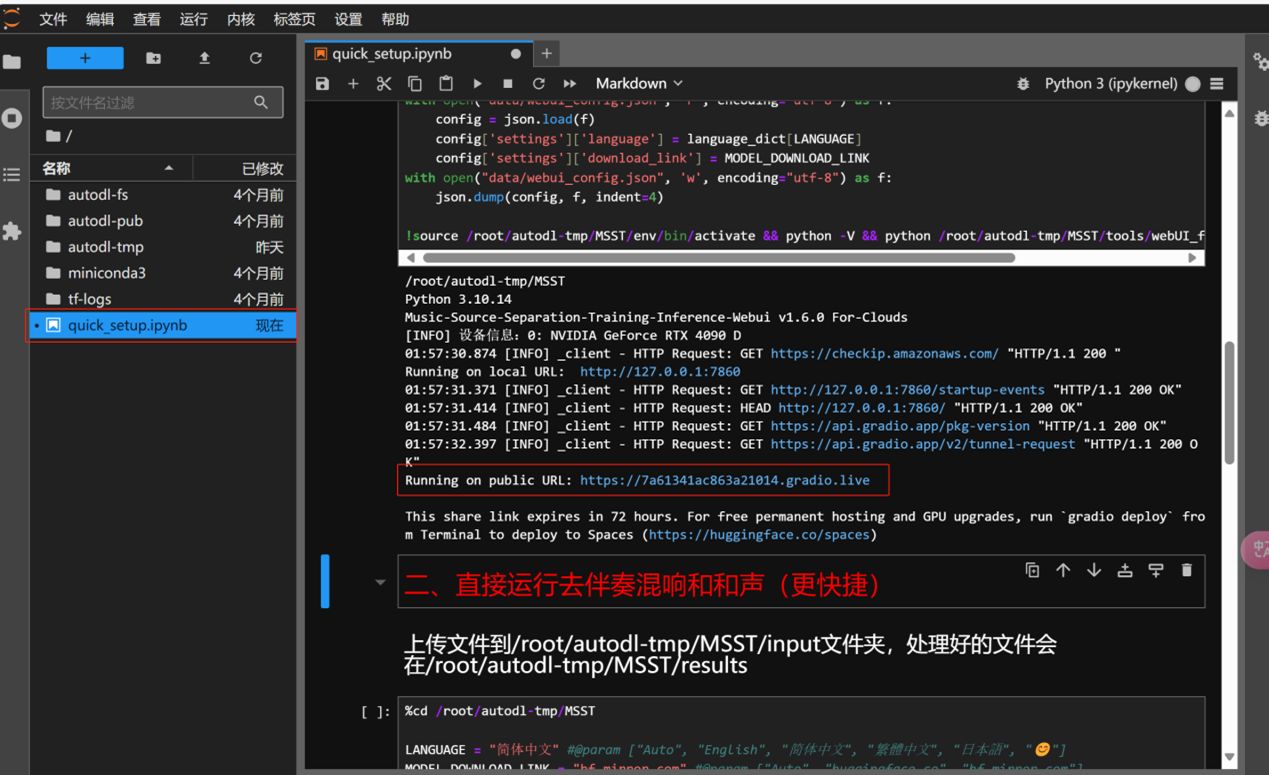
- 点击JupyterLab进入操作台,运行前面2段代码代开WebUI界面,后续操作与上述Colab一致,不再阐述。
- 分离音频被放在autodl-tmp/MSST/results文件夹下。
与Colab不同,分离音频无需重新下载上传步骤,后续音频清洗可直接将音频从results处粘到input处进行批量清洗。

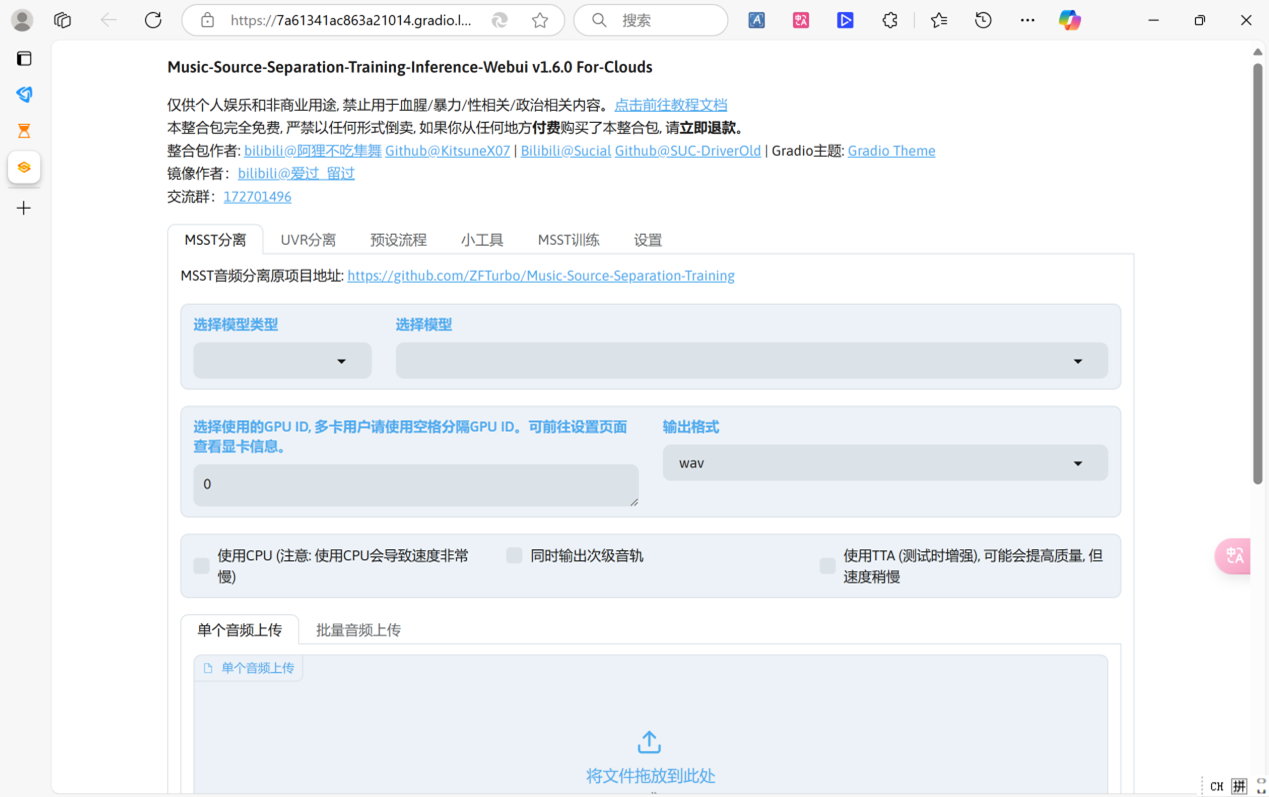
花儿不哭说Colab平台上的代码是他自己维护的,但AutoDL平台社区镜像的代码不是他维护的,两边我都尝试了,目前都可以使用。
音频分离网站
MVSEP网
- MVSEP网址:https://mvsep.com/zh/home
- 该网址模型也很多,但是免费模型分离出来的音频杂音比较多,不够纯净。
Vocalremover网
- 音频分离网站:https://vocalremover.org/zh/
模型训练
因目前收集的Colab平台模型代码bug比较多,模型训练及推理只在AutoDL平台进行。
AutoDL教程
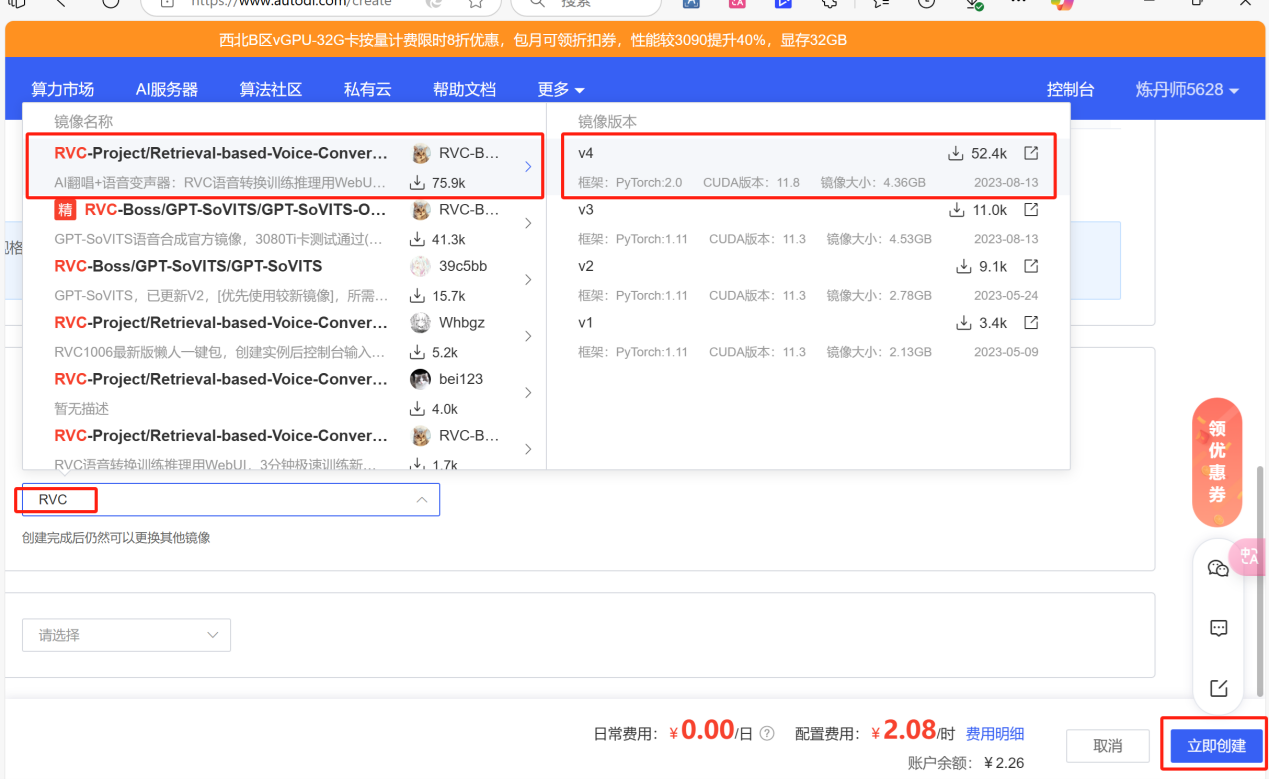
第一步:创建主机
- 选择一台空闲的主机,点击社区镜像,搜索框输入RVC后,选择RVC-Project的V4版本,点击立即创建。【V3和V4版本需要适配4090主机】
第二步:打开模型训练界面
- 在终端输入命令打开训练界面:cd /root/Retrieval-based-Voice-Conversion-WebUI && python infer-web.py –port 6006
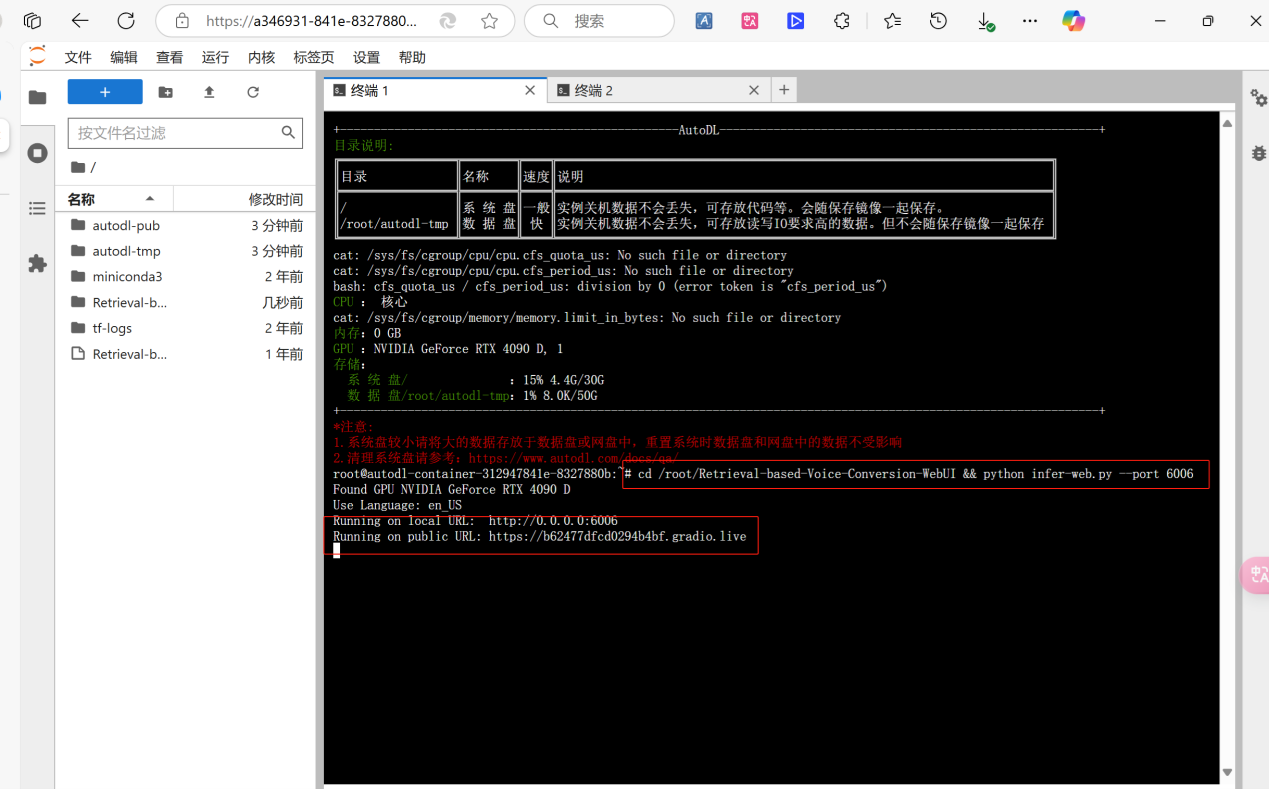
第三步:上传训练素材
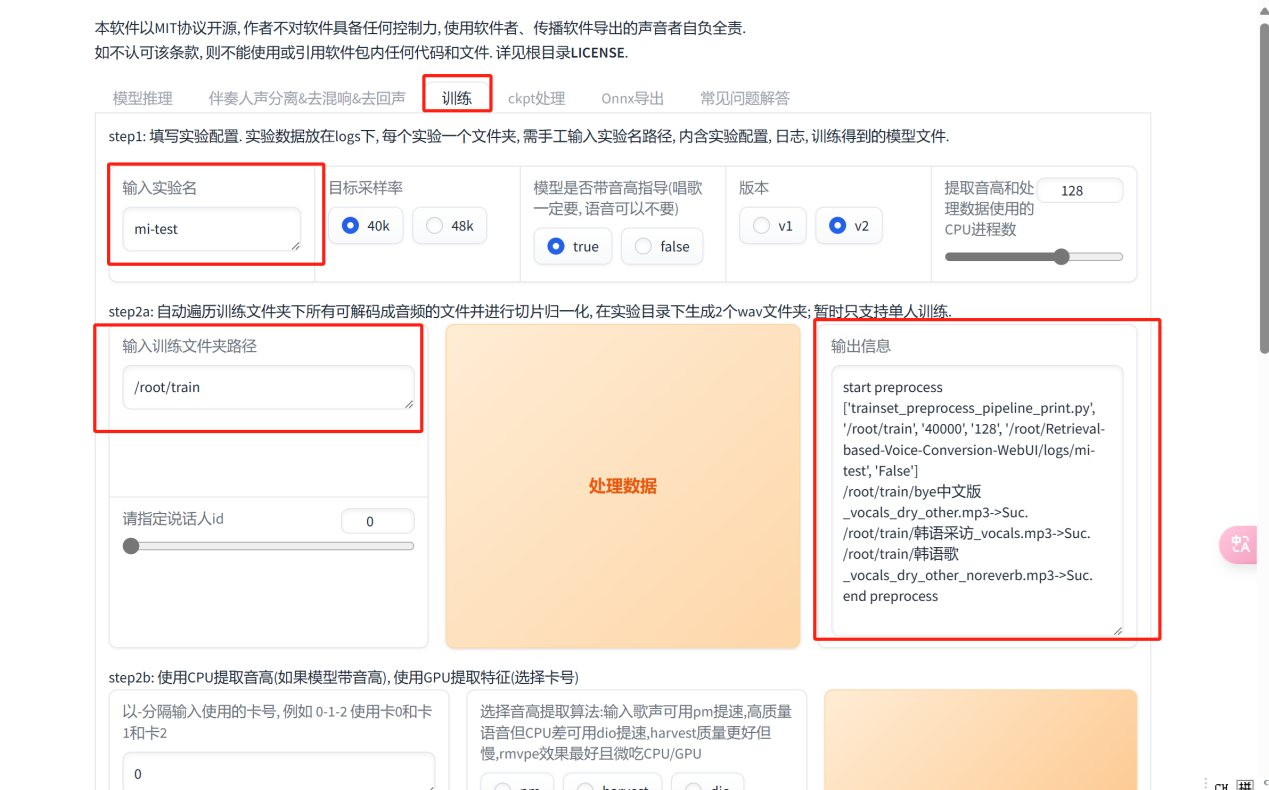
- 在界面创建一个名为train的文件夹,上传干声模型训练素材。
第四步:定义训练参数
- 实验名可以自定义,输入训练文件路径/root/train
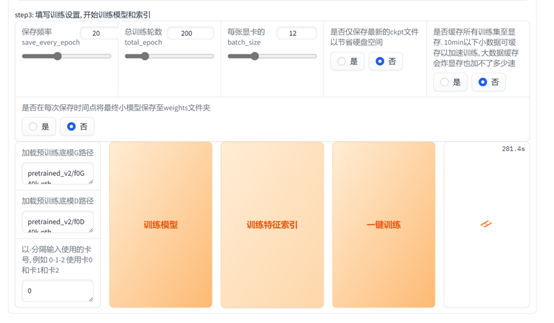
- 修改总训练轮数&保存频率【此处将训练轮数定为200,保存频率为20,因为轮数比较少的时候模型还是会带点口音,开源UP主说十几分钟的素材200-300轮即可】
- 最后点击一键训练,出现成功提示即可。
模型推理
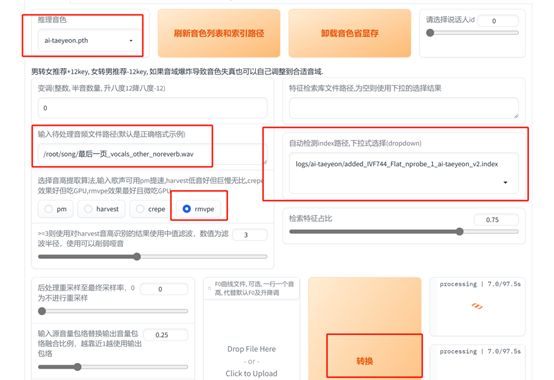
- 创建test文件夹,上传需要翻唱的歌曲干声素材
- 推理页面输入干声文件路径,选择rmvpe格式,点击转换
- 试听并点击下载推理结果
音频合成
安装破解版Au2025
- 详细安装教程:https://mp.weixin.qq.com/s/ab8utKqmKHI6iQnKlZ276Q
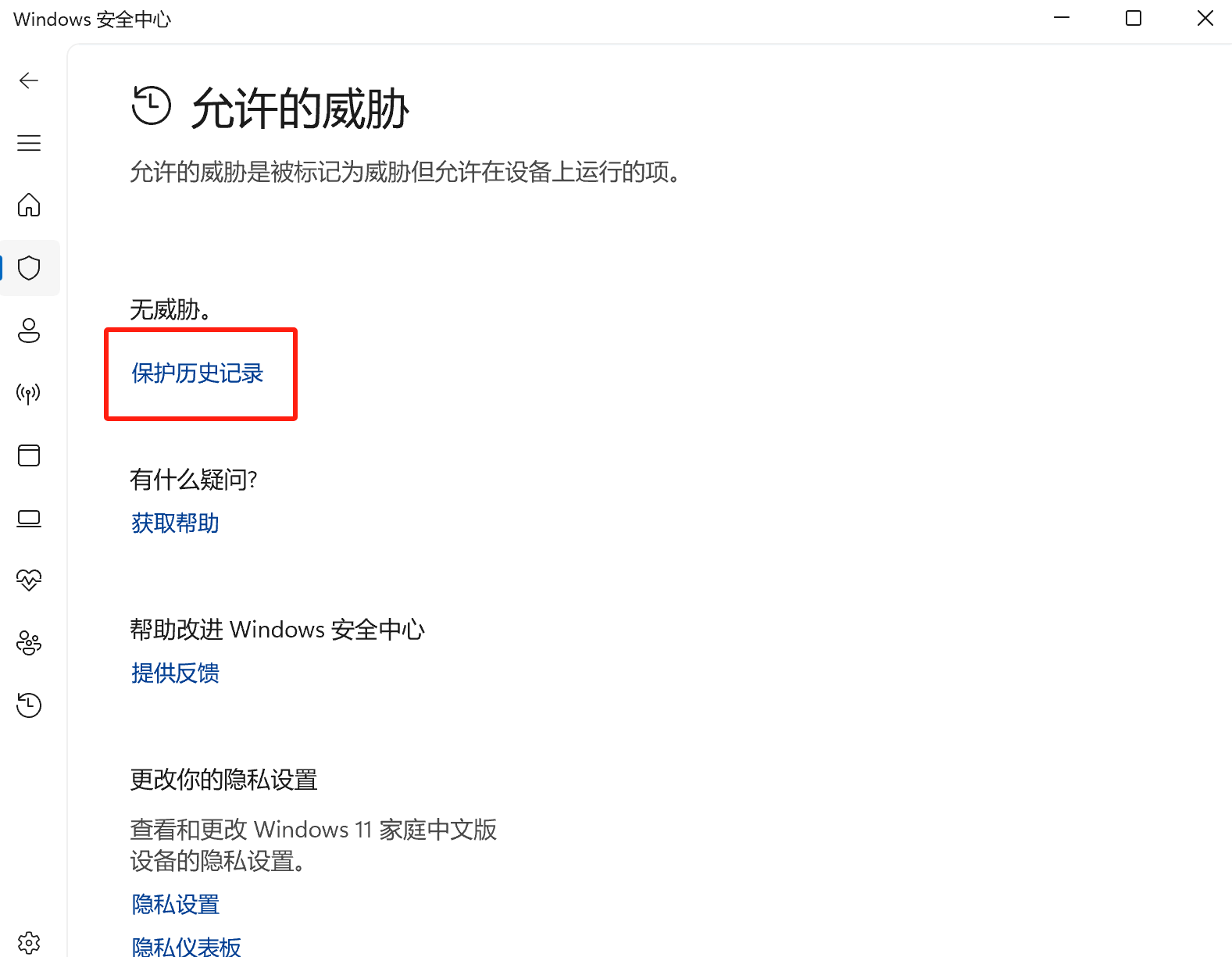
因为安装包中有破解补丁,所以安装前最好断网。其次,解压缩安装包后可能找不到破解补丁,应该是已经被系统的安全管家拦截,所以需要在 Windows安全中心-病毒和威胁防护-保护历史记录 中 查看以保护的威胁,将其进行还原。

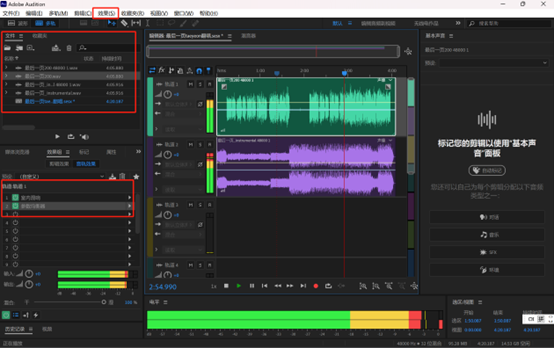
合成音频
- 将演绎的音频伴奏,AI推理结果拖入Au
- 增加音频效果:效果-混响-室内混响;效果-滤波与均衡-参数均衡器-人声增强
AI翻唱效果
Taeyeon中文原声
训练了100步的模型推理音频
训练了200步的模型推理音频
Huggingface上别人训练的模型推理音频
整体音色上是有点像的,我自己训练的模型和Huggingface模型推理音频相比,我自己训练的模型好像音调要更尖一点,主要是训练素材不同,感觉是我的训练素材里面有首比较高音的歌。最后整体效果AI翻唱的声音感觉还是有点生硬,一方面是模型训练问题,也可能是最后合成音频的时候技术加工不够。
 wechat
wechat alipay
alipay

